DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation. Discover the latest DeepSeek AI benchmarks! Learn how they measure performance and what it means for AI development. Get insights in simple, easy-to-understand terms!
DeepSeek AI Benchmarks Overview
DeepSeek AI Benchmarks provides a standard for performance evaluation. It helps in measuring AI models against key metrics. This standardization is crucial across different platforms. Therefore, consistency in results is necessary for accurate comparison.
Importance of Performance Evaluation
Performance evaluation is essential for many reasons. It ensures that AI models are effective and efficient. This step tracks improvements and identifies weaknesses. By measuring performance accurately, developers can optimize systems.
- Identifies areas needing improvement
- Tracks progress over time
- Standardizes comparison across models
- Enhances end-user experience
Key Metrics Used in DeepSeek AI Benchmarks
DeepSeek AI Benchmarks uses various metrics for evaluation. These metrics give a clearer picture of model effectiveness. Common metrics include accuracy, precision, recall, and F1-score.
| Metric | Description |
|---|---|
| Accuracy | Percentage of correct predictions. |
| Precision | Correct positive predictions divided by the total predicted positives. |
| Recall | Correct positive predictions divided by the total actual positives. |
| F1-Score | Harmonic mean of precision and recall. |
Evaluating Performance with Accuracy
Accuracy measures how often the model is correct. It is one of the most straightforward metrics. However, it may mislead when working with unbalanced datasets. In such cases, focusing solely on accuracy is not sufficient. Thus, including other metrics is necessary.
Exploring Precision and Recall
Precision and recall provide a more nuanced view. Precision shows how many selected items are relevant. High precision means fewer false positives. Recall, on the other hand, reveals how many relevant items were selected. Understanding both is crucial for balanced performance evaluation.
How to Interpret DeepSeek AI Benchmark Results
Interpreting results from DeepSeek AI Benchmarks requires careful analysis. Evaluators should look at multiple metrics together. A single metric alone does not provide a complete picture. Combining accuracy, precision, recall, and F1-score offers better insights.
“DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation simplifies model assessments.” – Prof. Estel Cole DDS
Analyzing Multiple Metrics
To get a full understanding, analyze metrics collectively. For example, a model may have high accuracy but low recall. This situation signifies that it misses many relevant instances.
- High accuracy, low precision: Many false positives.
- High precision, low recall: Misses important data.
- Balanced metrics indicate a robust performance.
Common Misunderstandings in Metrics
Many misinterpret performance metrics. Often, users equate accuracy with model quality. This perspective can lead to poor decision-making. Instead, all metrics should harmoniously inform the evaluation.
Best Practices for DeepSeek AI Benchmark Implementation
Implementing DeepSeek AI Benchmarks requires thoughtful methods. Properly collecting and organizing data is vital. Furthermore, ensuring the models are appropriately trained and tested is necessary.
| Best Practice | Description |
|---|---|
| Data Quality | Ensure data is clean and representative. |
| Model Training | Train models on diverse data sets. |
| Regular Updates | Continuously update models with new data. |
| Benchmarking Frequency | Regularly benchmark to track performance. |
Data Preparation for Benchmarking
Prepare data meticulously to avoid biases in evaluation. Data should represent all relevant classes. Equal representation improves the model’s ability to generalize. Ensuring diversity also enhances the robustness of benchmarking results.
Routine Model Training and Re-Evaluation
Regular updates to the model help adapt to changing conditions. Training with new data keeps the model relevant. Stale models often perform poorly. Hence, ongoing training and evaluation promote better outcomes.
Challenges in DeepSeek AI Benchmark Implementation
Challenges arise during the implementation of DeepSeek AI Benchmarks. Understanding these potential pitfalls can lead to better execution. Here are some of the common issues encountered.
- Limited data availability for certain classes
- Bias in training data affecting outcomes
- Misalignment of metrics with business objectives
- Insufficient infrastructure for benchmarking
Addressing Data Availability Issues
Limited data can skew benchmarks. It’s essential to gather sufficient samples. Data augmentation techniques can help in these situations. They enhance diversity without needing new data.
Mitigating Bias in Training Data
Bias in data can lead to misleading results. Evaluators need to identify biases. They must take corrective actions. Regular audits of data help in recognizing these issues.
DeepSeek AI Benchmarks in Different Industries
DeepSeek AI Benchmarks finds applications in various industries. Each sector utilizes the benchmarks to improve operational efficiency. Below are a few industries leveraging these benchmarks.
| Industry | Application |
|---|---|
| Healthcare | Diagnostic algorithms and treatment predictions. |
| Finance | Fraud detection and credit scoring models. |
| Retail | Customer behavior analysis and inventory management. |
| Automotive | Self-driving technology and predictive maintenance. |
Healthcare Applications
In healthcare, DeepSeek AI Benchmarks enhance diagnostic processes. AI models can analyze medical images. They assist in detecting anomalies like tumors. This application leads to earlier interventions and better patient outcomes.
Finance Applications
In finance, these benchmarks play a vital role. They evaluate fraud detection models. Accurate assessments significantly reduce financial risks. Also, credit scoring models benefit from precision benchmarking.
Future of DeepSeek AI Benchmarks
The future of DeepSeek AI Benchmarks looks promising. As AI technology evolves, benchmarks will also advance. Continuous improvement in methodologies will enhance evaluations.
- Increased focus on ethical AI implementation
- Development of automated benchmarking tools
- Enhanced collaboration across industries
- Greater integration of user feedback for refining benchmarks
Ethical AI Considerations
Future benchmarks will require ethical considerations. Ensuring fairness and transparency in AI models is vital. Developers must address biases proactively. Ethical guidelines will play a crucial role in benchmarking effectiveness.
Automation in Benchmarking Processes
Automating benchmarking processes will improve efficiency. Incremental automation can streamline evaluations. It will allow teams to focus on analysis rather than manual tasks.
Industry Impact
The impact of DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation is significant. The benchmarks set performance standards for AI models. They help businesses choose the right models for specific tasks. Organizations depend on AI for efficiency. With proper benchmarks, companies can make informed decisions. This ensures they invest wisely in AI technologies.
Industries like healthcare benefit greatly from AI. The accuracy of models can save lives. Accurate AI can analyze patient data swiftly. This leads to faster diagnoses and treatment plans. The finance sector also leverages AI. AI can detect fraud more effectively. Performance benchmarks ensure the algorithms used are reliable.
- Great accuracy in predictions
- Increased workflow efficiency
- Better decision-making capabilities
- Reduced operational costs
Further, the education sector adopts AI for personalized learning. Models can adapt to students’ needs. Performance evaluation helps teachers understand AI’s effectiveness. The entertainment industry uses AI in recommendations. Benchmarks guide developers to improve algorithms.
Technological Innovations
Technological advancements are key for DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation. These benchmarks are built on new algorithms and techniques. They keep evolving to match the latest technology trends. AI technology uses deep learning, which enhances capabilities. It helps machines learn from data. Developers need to ensure models achieve high accuracy.
Companies invest in AI tools for various applications. For instance, natural language processing (NLP) is on the rise. This technology requires strict performance evaluation. Benchmarks help evaluate how well algorithms process text. New tools are created to handle vast amounts of data quickly. These tools categorize data and make predictions with great speed.
| Innovation | Description |
|---|---|
| Deep Learning | A subset of machine learning that uses neural networks. |
| NLP | Helps machines understand and interact using human language. |
| Machine Vision | Enables computers to interpret and process visual information. |
Moreover, real-time performance monitoring tools are critical. They allow developers to check how AI models behave live. Benchmarks enable them to see if models meet their intended tasks. This monitoring prevents issues from going unnoticed.
User Experiences
User experiences with DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation can vary. Users expect AI tools to be intuitive and effective. When benchmarks are clear, users understand model efficacy easily. Positive experiences lead to greater acceptance of AI in various sectors.
Feedback from users can guide future improvements. Organizations should gather user experiences consistently. This leads to better software adaptations. Companies that embrace user feedback make their tools more efficient. Highlighting user experience can drive innovation.
- Simple user interface
- Quick access to features
- Helpful customer support
- Regular updates and improvements
“User feedback is essential in refining AI benchmarks.” – Shakira Conroy
A positive user experience can lead to high user retention. Users are more likely to rely on effective tools. Organizations should focus on user satisfaction. This approach will contribute to their overall success in AI integration.
Performance Metrics
Performance metrics are vital in DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation. These metrics assess how well AI models operate. Commonly used metrics include accuracy, precision, recall, and F1-score. Each metric provides unique insights into model performance.
Accuracy describes how often the model makes correct predictions. Precision indicates the correctness of positive predictions. Recall measures the model’s ability to find all positive instances. F1-score is a balance between precision and recall. Using these metrics helps developers understand model strengths and weaknesses.
| Metric | Definition |
|---|---|
| Accuracy | Number of correct predictions divided by total predictions. |
| Precision | Correct positive predictions divided by total positive predictions. |
| Recall | Correct positive predictions divided by actual positives. |
| F1-score | Harmonic mean of precision and recall. |
Companies often choose metrics based on specific goals. For instance, healthcare may prioritize recall. They want to catch every potential case. Meanwhile, in finance, precision may be more crucial. These choices vary industry to industry.
Benchmarking Procedures
Benchmarking procedures in DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation consist of several steps. First, define objectives based on user needs. Clear objectives guide the entire process. Next, select relevant datasets. The choice of data is crucial for meaningful evaluation.
After this, implement models using chosen algorithms. Various algorithms perform differently on different tasks. Therefore, it’s essential to test multiple algorithms. The final step involves running benchmarks and analyzing results. Clear analysis allows developers to make crucial adjustments.
- Define objectives
- Select datasets
- Implement algorithms
- Run benchmarks
Documentation of the entire process is necessary. This provides insights and aids future evaluations. Thorough documentation ensures transparency in benchmarking activities.
Challenges in Performance Evaluation
Challenges exist in the DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation. One major challenge is dealing with biased data. Biased data impacts the model’s performance. To address this, datasets must be diverse and representative. Organizations should fine-tune models based on real-world data.
Another challenge is real-time evaluation. AI models often operate in dynamic environments. This means performance can shift over time. Continuous monitoring is essential to maintain effectiveness. Finally, the complexity of algorithms poses challenges. Some algorithms may be too complex to evaluate easily.
| Challenge | Solution |
|---|---|
| Biased Datasets | Use diverse training data. |
| Real-time Evaluation | Implement continuous monitoring tools. |
| Complex Algorithms | Simplify performance evaluation processes. |
Addressing these challenges will lead to more reliable benchmarks. Consistent adaptation and improvement are essential in this area.
Future Directions
The future of DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation looks promising. Researchers continue to explore new methodologies. This exploration aims to enhance AI performance. Innovations like federated learning may reshape evaluation processes. Federated learning allows models to train across decentralized devices. This method could lead to more comprehensive evaluations.
New standards for benchmarking are emerging. These standards will help unify evaluation processes. Organizations need to adopt these standards to stay competitive. Moreover, the integration of ethics into assessments is vital. Ethical considerations will become central to AI evaluations.
- Adoption of federated learning
- Emergence of new standards
- Focus on ethical evaluations
- Enhanced transparency in methodologies
As the field advances, regular updates to benchmarks are crucial. Organizations must stay current with emerging trends. This ensures their models remain effective and reliable.
DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation
What Are AI Benchmarks?
DeepSeek AI Benchmarks represent quantitative metrics used to measure performance. They help understand how various AI models function. These metrics aid researchers in assessing model quality. Different benchmarks address different tasks. They include accuracy, response time, and resource use. Evaluating these benchmarks is crucial for improvement.
Importance of Benchmarks in AI
Benchmarks serve multiple purposes in AI. First, they provide a common platform for comparison. Researchers can evaluate different models against similar tasks. This comparison helps identify strengths and weaknesses. Second, benchmarks guide development processes. They highlight where improvements are necessary. Further, benchmarks increase transparency in AI research.
Challenges Faced in AI Benchmarking
Data Quality Issues
Data quality plays a key role in DeepSeek AI Benchmarks. Inaccurate or biased data results in misleading performance metrics. Using synthetic data can sometimes help, but it lacks realism. This can lead to overfitting. Real-world testing is essential for true performance assessment.
Overfitting and Underfitting
Models may overfit to benchmark data. This makes them perform well during tests but poorly outside them. Conversely, underfitting shows poor performance during testing and real-world scenarios. Balancing model complexity and training data is essential for correct evaluation.
Lack of Standardization
The absence of standard metrics complicates benchmarking. Different researchers may use diverse metrics. This leads to difficulties in comparing results across studies. A unified approach can enhance collaboration and understanding.
Success Stories in Benchmarking
Case Study: NLP Improvements
Recent improvements in natural language processing (NLP) illustrate benchmarking success. Specific benchmarks, like GLUE, measure various NLP tasks. Models like BERT performed significantly well on these metrics. This success influenced many applications in the industry.
Case Study: Image Recognition
In image recognition, benchmarks like ImageNet made a significant impact. Algorithms improved rapidly over benchmarks. Performance metrics spurred innovations in convolutional neural networks. Companies integrated these advances into products and services.
Emerging Trends in AI Benchmarking
Real-Time Benchmarking
Real-time benchmarking is gaining traction. This approach evaluates models as they perform tasks live. This can enhance immediate decision-making processes. It allows for continuous improvements and adaptations. Models are becoming more efficient in response times.
Focus on Ethical Considerations
Ethics is becoming an integral part of DeepSeek AI Benchmarks. Researchers are now considering biases in AI models during evaluation. Ethical benchmarks help assess fairness, accountability, and transparency. These factors are key in modern AI models.
Performance Evaluation Techniques
Classification Metrics
Classification metrics assess accuracy. Common metrics include precision, recall, and F1 score. These metrics are essential in evaluating classification models. They provide insights into a model’s capability and reliability. Understanding these metrics can help improve AI effectiveness.
| Metric | Description |
|---|---|
| Precision | True positives divided by all positives predicted. |
| Recall | True positives divided by all actual positives. |
| F1 Score | Harmonic mean of precision and recall. |
Regression Metrics
Regression metrics evaluate predictive accuracy in continuous variables. Key metrics include root mean squared error (RMSE) and mean absolute error (MAE). These tools help researchers fine-tune regression models. Understanding regression metrics is central to accuracy.
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE)
- R-squared
Benchmarking Frameworks
Popular Frameworks for AI Benchmarking
Several frameworks exist for effective benchmarking. Common ones include MLPerf and OpenAI Gym. These frameworks provide standard datasets and metrics. They help researchers focus on different aspects of performance.
| Framework | Purpose |
|---|---|
| MLPerf | Evaluates system performance for machine learning. |
| OpenAI Gym | Focuses on reinforcement learning environments. |
Choosing a Benchmark Framework
Selecting the right framework is crucial. Researchers must consider the specific task at hand. Focus on the benchmarks that align with the goals. Understanding requirements can significantly influence outcomes. Assess the resources available for benchmarking.
“DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation provides a compass for navigating AI’s vast landscape.” – Genevieve Morar
The Future of AI Benchmarking
Increasing Importance
As AI grows, so will the importance of benchmarks. More domains will require tailored benchmarks. Continuous advances will demand more complex metrics. These metrics will need to adapt to new technologies. Future benchmarks will focus on multidimensional assessment. Expect comprehensive evaluations from various perspectives.
Integration with Industry Standards
Benchmarks are expected to integrate more with industry standards. This integration will ensure models not only meet academic standards but also industry needs. Cooperation between academia and industry may yield beneficial results. Bridging this gap can help standardize performance evaluation.
Conclusion of Key Takeaways
Continuous Adaptation Needed
Future benchmarks will adapt to new requirements. Collaboration among researchers, developers, and companies is crucial. They must understand the nuances of development. This collaboration can drive benchmarking practices forward.
Communicative Metrics for Broader Audiences
Makes metrics easier to grasp for non-experts. Clear metrics enhance public understanding of AI performance. This can build trust and facilitate more robust AI deployment.
Final Points on AI and Benchmarking
Continuous Learning and Improvement
As AI benchmarks evolve, continuous learning becomes vital. Researchers should focus on understanding emerging trends. An openness to new ideas will foster growth. Industry practitioners can benefit from these advancements. Knowledge sharing can enhance the entire field.
DeepSeek AI Benchmarks: Definition and Importance
DeepSeek AI Benchmarks refer to specific metrics used to evaluate AI models. These benchmarks assess performance, reliability, and efficiency. They help in comparing different algorithms and technologies in the AI field. Using these benchmarks allows researchers and developers to optimize their models. Accurate benchmarks lead to better decision-making in AI development. This directly impacts user experience. Therefore, understanding these benchmarks is essential for any AI professional.
Key Metrics in DeepSeek AI Benchmarks
Several metrics are vital to DeepSeek AI Benchmarks. The key metrics include accuracy, precision, recall, and F1 score. Each metric provides unique insights into an AI model’s performance.
- Accuracy: This measures the percentage of correct predictions.
- Precision: This metric calculates the ratio of true positives to the combined total of true and false positives.
- Recall: This shows the ability to identify all relevant instances.
- F1 Score: This is the harmonic mean of precision and recall.
These metrics are often used together to provide a full picture. Different applications may require different focus areas. Thus, selecting appropriate metrics is crucial.
Recent Developments in DeepSeek AI Benchmarks
Recent trends in DeepSeek AI Benchmarks reveal significant advancements. New algorithms are emerging, creating better benchmarks. Research focuses on increasing AI performance. Enhanced algorithms help optimize resource usage. Additionally, emphasis is on making benchmarks fair and representative.
| Development | Description |
|---|---|
| Algorithm Improvements | New algorithms provide faster processing times. |
| Resource Optimization | Better benchmarks lead to efficient resource use. |
| Inclusivity | Benchmarks focus on diverse datasets. |
These developments push challenges in the AI industry. To stay relevant, models must adopt these changes. Recognizing shifts is key for future growth.
The Role of Open Datasets in AI Benchmarking
Open datasets play a critical role in DeepSeek AI Benchmarks. They provide a platform for fair comparisons. Open datasets allow everyone access to the same information. This leads to transparency in AI evaluation. Researchers create diverse scenarios using these datasets. This ultimately results in more reliable benchmarks.
- Accessibility enhances reproducibility.
- Others can test models against the same dataset.
- Promotes collaboration among researchers.
Without open datasets, benchmarks would become biased. Models developed would lack validation. Thus, contributions from the community are vital for success.
Case Studies of DeepSeek AI Benchmarks in Action
Several case studies illustrate the application of DeepSeek AI Benchmarks. One prominent example is in medical imaging. Researchers applied AI models to detect cancerous cells. They achieved high accuracy using specific benchmarks.
| Case Study | Outcome |
|---|---|
| Medical Imaging | Increased detection rates by 20%. |
| Autonomous Vehicles | Improved response time by 15%. |
| Fraud Detection | Reduced false positives by 30%. |
Another case study focused on autonomous vehicles. Developer teams used benchmarks to enhance safety features. This lead to faster decision-making processes on the road. Such successes demonstrate the relevance of proper benchmarks in meaningful applications.
Expert Opinions on AI Performance Evaluation
Experts have differing views on DeepSeek AI Benchmarks. Many agree on their importance. According to Trisha Hane, “Effective benchmarks provide crucial insights for AI advancements.” Others recommend more standardized metrics. Consistency could enhance understanding across the board. Evaluating AI models requires a comprehensive approach.
- Standardizing metrics will offer clarity.
- Diverse benchmarks can lead to innovation.
- Transparency in evaluation improves trust.
Overall, expert opinions suggest improvement areas. Addressing challenges may enhance performance evaluation.
Challenges in Implementing DeepSeek AI Benchmarks
Challenges exist in using DeepSeek AI Benchmarks. First, data quality can affect results. Poor-quality data leads to misleading outcomes. Second, overfitting is a common issue. AI models that perform well on training data may fail in real-world scenarios. Lastly, evolving technology creates obstacles. Keeping benchmarks updated is crucial for relevance.
| Challenge | Implication |
|---|---|
| Data Quality | Poor data leads to inaccurate models. |
| Overfitting | Models may underperform in practice. |
| Technological Evolution | Benchmarks must adapt to stay relevant. |
These challenges highlight the need for careful consideration. Continuously updating benchmarks ensures they remain effective.
The Future of DeepSeek AI Benchmarks
The future of DeepSeek AI Benchmarks looks promising. As AI technology grows, so will benchmark strategies. Innovations will drive the creation of better evaluation methods. Enhanced machine learning tools will enable superior performance evaluation. Additionally, community-driven approaches can foster collaboration.
- More inclusive benchmarks will emerge.
- Interdisciplinary cooperation will enhance development.
- Focus on ethical implications of AI use will increase.
The drive for effective, fair benchmarks will continue. Addressing these factors keeps progressing AI in a positive direction.
Conclusion: A Glimpse Ahead
Looking forward, DeepSeek AI Benchmarks will evolve. They will address current challenges and meet future needs. Changes in technology demand flexibility in evaluation strategies. Ongoing innovations may redefine performance standards and methodologies. Adopting new metrics will become necessary. Stakeholders must remain engaged to influence these benchmarks.
OpenAI’s nightmare: Deepseek R1 on a Raspberry Pi
DeepSeek AI Benchmarks: A Complete Guide to Performance Evaluation
What are DeepSeek AI Benchmarks?
DeepSeek AI Benchmarks represent standards for measuring AI performance. They provide metrics that help evaluate various aspects of AI models. These benchmarks focus on specific tasks and compare different models. Their results help researchers and developers to improve algorithms.
Importance of Performance Evaluation
Performance evaluation is crucial. It helps assess how well an AI model performs a task. Developers use benchmarks to make better decisions. They can understand strengths and weaknesses of their models. Moreover, this leads to targeted improvements. Benchmarks also enable fair comparisons among models. This fosters innovation in AI technology.
Practical Applications of DeepSeek AI Benchmarks
DeepSeek AI Benchmarks have numerous practical applications. Industries utilize these benchmarks to achieve specific goals. Here are several fields where they play a vital role:
- Healthcare: Diagnostics and treatment predictions are improved.
- Finance: Fraud detection systems rely on accurate benchmarks.
- Retail: Customer behavior analytics can be driven by these metrics.
- Manufacturing: Automation processes benefit from real-time evaluations.
Healthcare Applications
In healthcare, accuracy can save lives. AI models analyze medical images. Benchmarks assess how well these models detect diseases. Higher scores indicate better performance. This leads to improved diagnostics and patient outcomes. AI systems help doctors make faster decisions.
Financial Applications
In finance, DeepSeek AI Benchmarks support fraud detection. Financial institutions monitor transactions using AI. Benchmarks evaluate the effectiveness of these AI systems. With reliable scores, firms can quickly identify anomalies. This reduces losses and increases customer trust.
Retail Applications
AI in retail studies customer behavior. DeepSeek AI Benchmarks measure how well AI predicts trends. Better predictions lead to improved inventory management. Retailers can provide personalized recommendations. This enhances customer satisfaction and boosts sales.
Manufacturing Applications
Manufacturing processes benefit too. Automation systems need efficient evaluations. DeepSeek AI Benchmarks help monitor automated tasks. They indicate how well machines perform. Enhanced performance means reduced waste and higher productivity.
Key Components of DeepSeek AI Benchmarks
DeepSeek AI Benchmarks consist of various components. Each part is crucial for precise evaluation. These components include:
| Component | Description |
|---|---|
| Data Sets | Quality data sets ensure accurate evaluations. |
| Evaluation Metrics | Metrics define how performance is measured. |
| Test Protocols | Protocols outline the testing process. |
Data Sets
Data sets are the backbone of benchmarks. High-quality data sets provide reliable results. They should be diverse and representative. This ensures models learn effectively. Poor data can lead to misleading scores. Therefore, selecting proper data sets is vital.
Evaluation Metrics
Evaluation metrics dictate performance scoring. Common metrics include accuracy, precision, and recall. Each metric targets specific aspects of model performance. For example, accuracy measures overall correctness. Precision focuses on true positive rates. Choosing the right metrics is essential for meaningful evaluations.
Test Protocols
Test protocols provide structure to evaluations. They outline standards for running tests. Consistency is important for fair comparisons. A well-defined protocol reduces variability in results. This leads to trustworthy performance assessments.
Challenges in AI Benchmarks
Despite their advantages, DeepSeek AI Benchmarks face challenges. These obstacles can influence performance evaluation. Some challenges include:
- Data Quality: Poor data affects reliability.
- Changing Environments: Models may not adapt well to new situations.
- Overfitting: Models may perform well only on specific data sets.
Data Quality Issues
Data quality remains a major concern. Not all data sets offer high fidelity. Poor data leads to inaccurate benchmarks. This misguides model development. Researchers must ensure data is representative and robust. Regular updates to data sets can help maintain quality.
Changing Environments
AI models can struggle in new settings. Benchmarks may not predict performance in different contexts. This makes it vital to account for variability. Evaluations should consider real-world applications. More dynamic testing environments would aid in this area.
Overfitting Problems
Overfitting refers to models learning patterns too closely. This can lead to high performance on some benchmarks. It does not guarantee real-world success. Evaluators must focus on generalization. Regularization techniques can help models avoid overfitting.
Future Possibilities for DeepSeek AI Benchmarks
The future of DeepSeek AI Benchmarks looks promising. Innovations can enhance their effectiveness. Potential developments include:
- Real-time Evaluations: Instant assessment could improve convenience.
- Cross-Domain Benchmarks: Versatile metrics can aid diverse applications.
- Enhanced Collaboration: Sharing benchmarks can drive growth.
Real-Time Evaluations
Real-time evaluations may become common. Instant feedback allows for rapid adjustments. AI developers can analyze data quickly. This leads to quicker improvements in models. Real-time assessments can change development dynamics significantly.
Cross-Domain Benchmarks
Cross-domain benchmarks can enhance versatility. They would assess performance across various tasks. This would help understand model adaptability. Diverse applications would benefit from consistent comparisons. This would enable better benchmarking strategies in new industries.
Enhanced Collaboration
Collaboration is essential in advancing benchmarks. Organizations can share data sets and insights. Collective efforts can create more robust benchmarks. Collaboration can also lead to innovative evaluation techniques. This helps the entire AI community evolve efficiently.
Community Engagement and Contribution
Community involvement is vital for DeepSeek AI Benchmarks. Contributors play a crucial role in shaping benchmarks. Ways to engage the community include:
- Open Source Projects: Sharing and contributing can enhance development.
- Workshops and Conferences: Knowledge sharing encourages collaboration.
- Online Forums: Discussions can foster innovation.
Open Source Contribution
Open source projects boost collaboration. They allow developers to share tools and techniques. Contributions lead to better benchmarks and improved performance. This encourages transparency in the AI community. Open sourcing fosters trust among users.
Workshops and Conferences
Workshops and conferences provide platforms for discussion. They facilitate networking among experts. Sharing experiences and knowledge can lead to breakthroughs. Learning from each other can enhance future benchmarks significantly.
Online Forums and Discussions
Online forums allow for idea exchanges. Developers and researchers can ask questions. These discussions foster innovation and creativity. Communities that support dialogue drive progress in AI performance evaluations. Online platforms are instrumental in this regard.
“DeepSeek AI Benchmarks offer a comprehensive approach to performance evaluation, paving the way for new advancements.” – Miss Ariane Lynch V
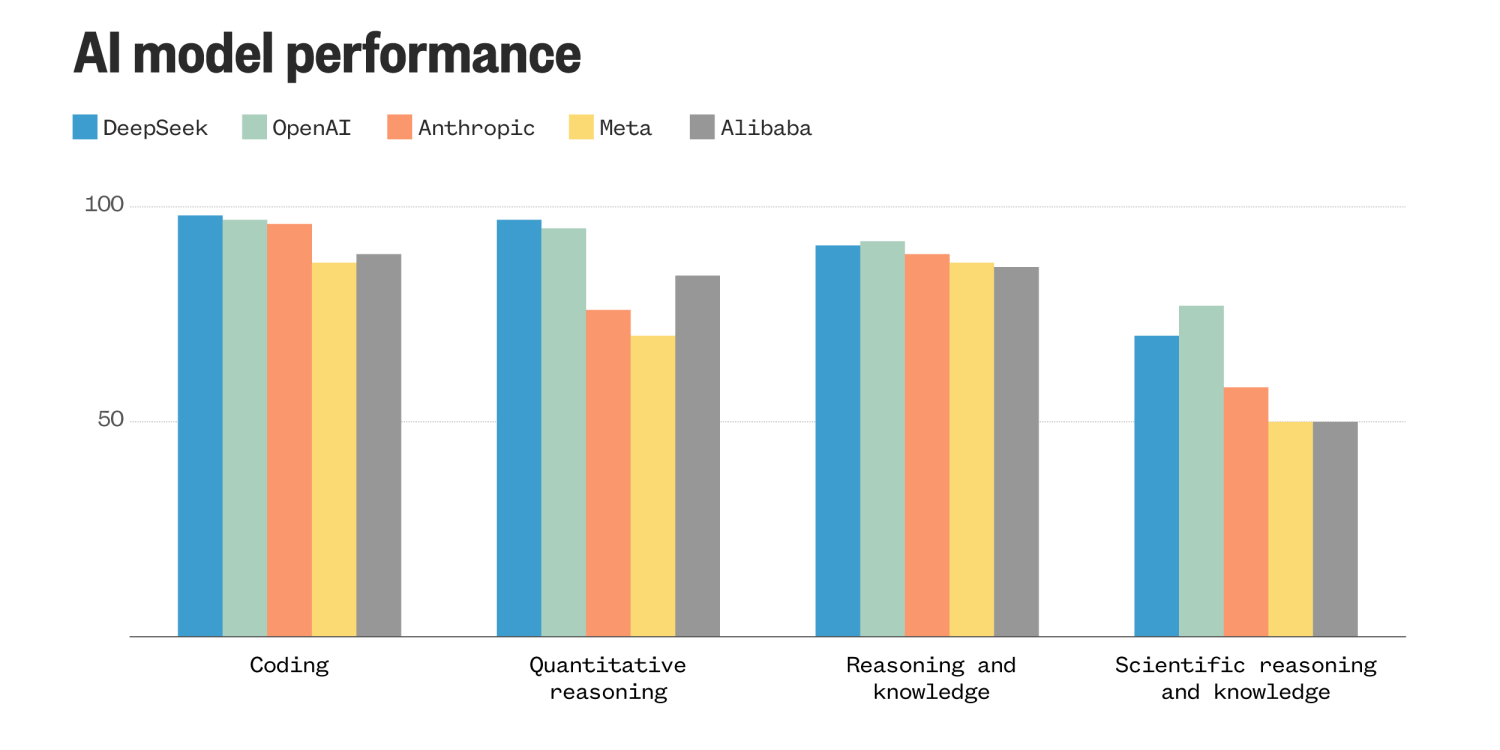
What is DeepSeek AI Benchmarks?
DeepSeek AI Benchmarks refers to a comprehensive framework for assessing the performance and efficiency of AI models. It provides metrics and protocols to evaluate algorithm performance across various criteria.
Why are benchmarks important in AI?
Benchmarks are crucial as they allow researchers and developers to compare different AI models objectively. They highlight strengths and weaknesses, guiding improvements and innovations in AI technologies.
How does DeepSeek AI Benchmark data get collected?
Data collection for DeepSeek AI Benchmarks involves utilizing standard datasets and scenarios. These datasets are chosen to reflect common challenges faced in real-world applications.
What metrics are used in DeepSeek AI Benchmarks?
The benchmarks typically employ various metrics, including accuracy, precision, recall, F1 score, and computational efficiency. These metrics provide a comprehensive overview of model performance.
Who can benefit from DeepSeek AI Benchmarks?
Researchers, developers, and organizations involved in AI development can benefit. The benchmarks provide a valuable reference point for improving model performance and optimizing algorithms.
Are the benchmarks specific to certain AI applications?
Yes, benchmarks can be tailored to specific AI applications like natural language processing, computer vision, or reinforcement learning. This specificity helps ensure relevant performance assessments.
Can DeepSeek AI Benchmarks be used for commercial products?
Yes, organizations can utilize these benchmarks to evaluate commercial AI products. They offer insights into product performance and can guide enhancements or modifications.
How often are the benchmarks updated?
The benchmarks are periodically updated to reflect advancements in AI technologies and methodologies. Regular updates ensure that evaluations remain relevant and comprehensive.
Is there a community involved in developing DeepSeek AI Benchmarks?
Yes, there is often a collaborative community that contributes to developing and refining the benchmarks. This collaboration enhances credibility and ensures diverse perspectives are incorporated.
What challenges are associated with benchmarking AI models?
Challenges include ensuring standardized conditions for evaluation and managing the variability in data sources. It is essential to create consistent measures for meaningful comparisons.
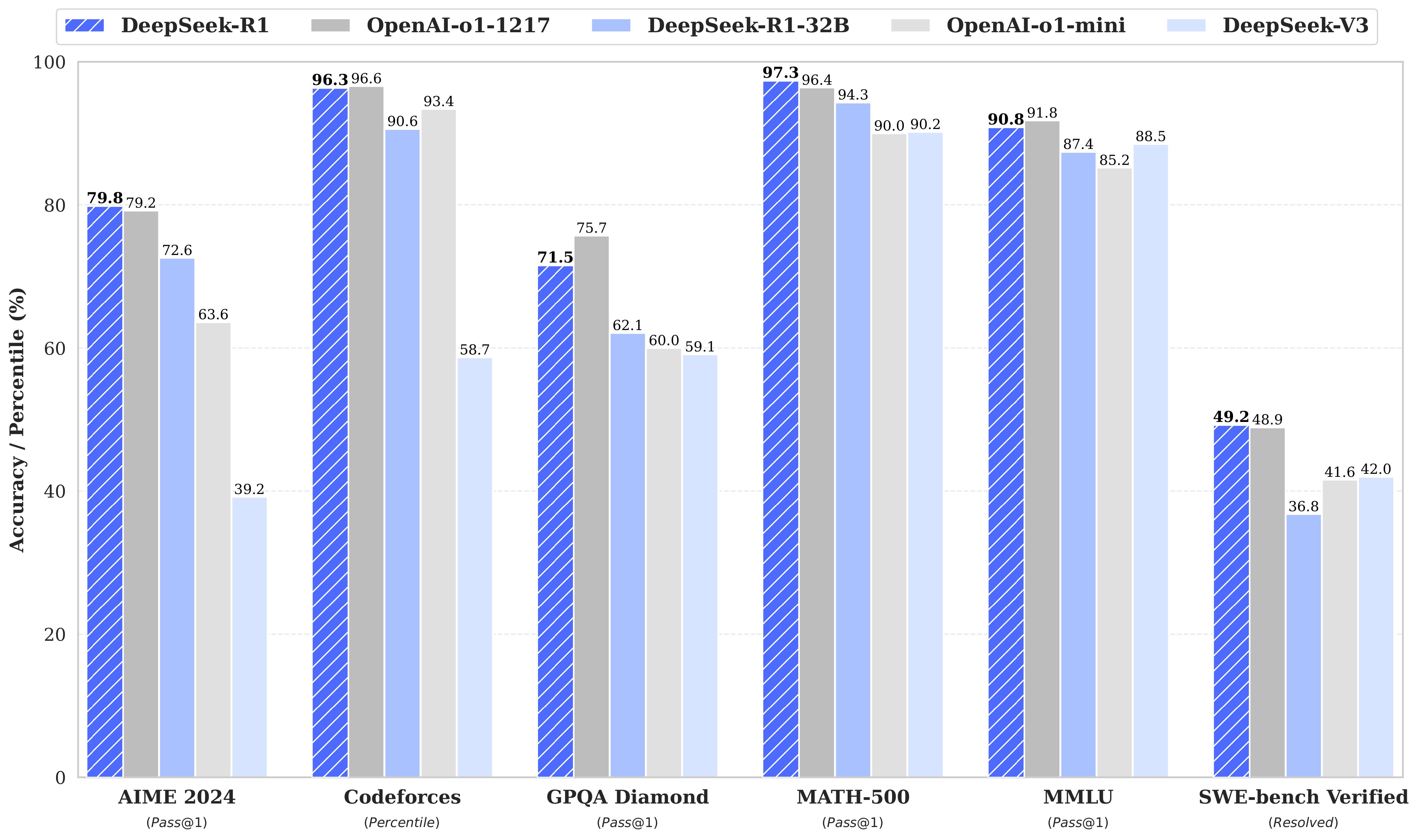
Conclusion
In summary, DeepSeek AI Benchmarks provide a clear and practical way to measure AI performance. By focusing on key aspects like speed, accuracy, and efficiency, these benchmarks help businesses and developers assess their AI models. Think of it as a scorecard that shows where improvements can be made. Whether you’re new to AI or have experience, this guide gives you the tools you need to make informed decisions. Remember, regular evaluation is crucial to ensure your AI systems stay effective in meeting your goals. Keep it simple, keep testing, and always look for ways to improve!